
Apache Hadoop YARN (Yet Another Resource Negotiator) is a cluster management technology. It decouples MapReduce’s resource management and scheduling capabilities from the data processing component, enabling Hadoop to support more varied processing approaches and a broader array of applications. YARN, (or sometimes called as MR2), is an extended and an improved version of MR1. It was designed to enable greater sharing, scalability, and reliability of a Hadoop cluster. The MapReduce functionality has been replaced with a new set of daemons that opens the framework to new processing models.
Some of the key features of YARN…
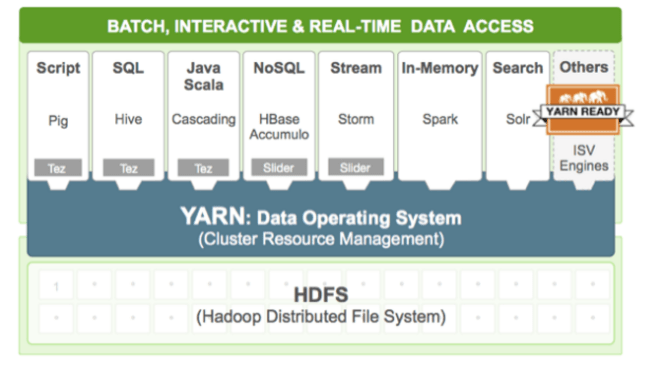
- YARN is the architectural center of Hadoop that allows multiple data processing engines such as interactive SQL, real-time streaming, data science and batch processing to handle data stored in a single platform.
- YARN supports multi-tenancy i.e. YARN allows multiple access engines (either open-source or proprietary) to use Hadoop as the common standard for batch, interactive and real-time engines that can simultaneously access the same data set.
-
- YARN’s dynamic allocation of cluster resources improves utilization over more static MapReduce rules used in early versions of Hadoop.
-
- YARN’s ResourceManager focuses exclusively on scheduling and keeps pace as clusters expand to thousands of nodes managing petabytes of data.
-
- Existing MapReduce applications developed for Hadoop MR1 can run YARN without any disruption to existing processes that already work.
Now, let us take a look at the architecture of YARN and see the functions of each component.
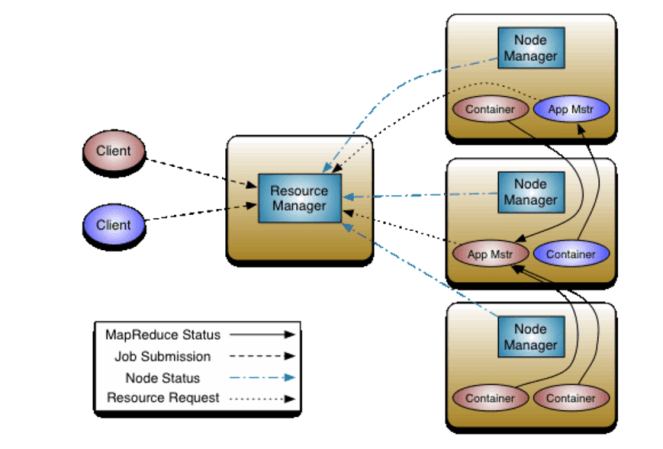
Resource Manager
- Is the authority that arbitrates resources among all the applications in the system.
- It has two main components: Scheduler and ApplicationsManager.
Scheduler
- It is responsible for allocating resources to the various running applications.
- It performs no monitoring or tracking of status for the application.
- It offers no guarantees about restarting failed tasks either due to application failure or hardware failures.
- It schedules based on the resource requirements of each application.
- It has a pluggable policy plug-in, which is responsible for partitioning the cluster resources among the various queues, applications etc. The current Map-Reduce schedulers such as the CapacityScheduler and the FairScheduler would be some examples of the plug-in. The CapacityScheduler supports hierarchical queues to allow for more predictable sharing of cluster resourcesApplications Manager
- It is responsible for accepting job-submissions.
- When a job is submitted, it negotiates the first container for executing the application specific ApplicationMaster
- It provides the service for restarting the ApplicationMaster container on failure.
Node Manager
- The NodeManager is the per-machine framework agent who is responsible for containers, monitoring their resource usage (cpu, memory, disk, network) and reporting the same to the ResourceManager/Scheduler.
Application Master
- The per-application ApplicationMaster has the responsibility of negotiating appropriate resource containers from the Scheduler, tracking their status and monitoring for progress.
For more information, please read Apache Hadoop Page or Hortonworks Page. References to this article are picked up from the above two pages.
