
In the previous post, we saw an introduction to Apache Storm, it’s characteristics and different use cases. Now, let us take a look at the Apache Storm architecture below –
A storm cluster is similar to a Hadoop cluster. In a Hadoop cluster, we run what is called as MapReduce jobs, but in Storm we run Topologies. The key difference between a MapReduce job and a Topology is that a MapReduce job eventually finishes, whereas, a topology processes messages forever (until it’s killed).
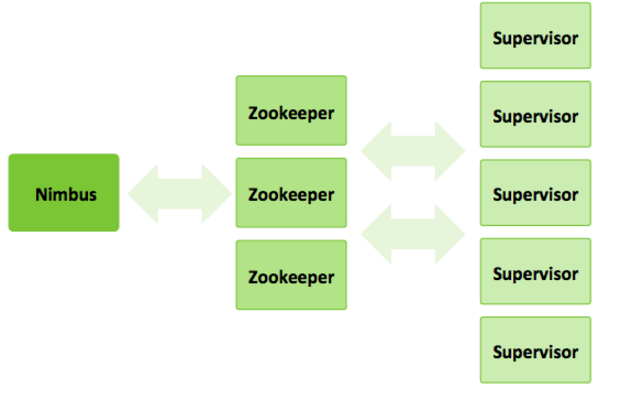
A storm has three sets of nodes –
- Nimbus Node
- Zookeeper
- Supervisor
Nimbus Node
Nimbus node is the master node and is similar to the Hadoop JobTracker. It’s main tasks include –
- Uploading the computations for execution.
- Distribution of code in the cluster.
- Launching workers across the cluster.
- Assigning tasks to machines.
- Monitoring computation and relocating resources or workers as and when needed.
- Monitoring failures.
Zookeeper Node
- Zookeeper node coordinates the storm cluster. All the coordination between Nimbus and Supervisors is done through Zookeeper.
- In addition to this, since the Nimbus daemon and Supervisor daemons are fail-fast and stateless; all state is kept in Zookeeper or on local disk. This means you can kill -9 Nimbus or the Supervisors and they’ll start back up like nothing happened. This design leads to Storm clusters being incredibly stable.
Supervisor Node
Each worker node runs a daemon called the Supervisor.
- Supervisor node communicates with the Nimbus node through zookeeper.
- It listens for work assigned to its machine and starts and stops worker processes as necessary based on what Nimbus has assigned to it.
- It starts or stops workers according to the signals from Nimbus node.
- Each worker process executes a subset of a topology; a running topology consists of many worker processes spread across many machines.
